AI that runs in your browser. No cloud required.
Chat with open source LLMs powered by WebGPU. Everything runs in your browser — your data never leaves your machine. Free, private, and fast.
Private by Design
Your conversations never leave your device.
All AI inference runs locally on your GPU via WebGPU. There's no server, no API calls, no telemetry. Once the model is loaded, it even works offline.
1
100% Local Inference
The model runs entirely in your browser tab. No data is transmitted anywhere.
2
Cached for Speed
Model files are cached in your browser. Subsequent visits load in seconds.
3
Works Offline
Once loaded, chat works without any internet connection.
0 bytes
sent to any server
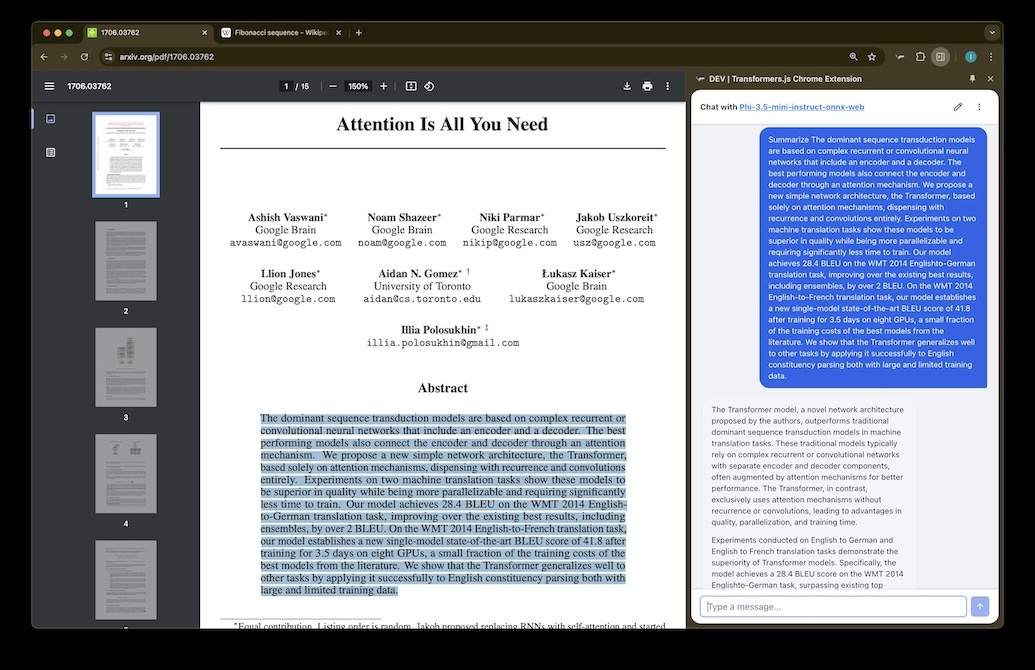
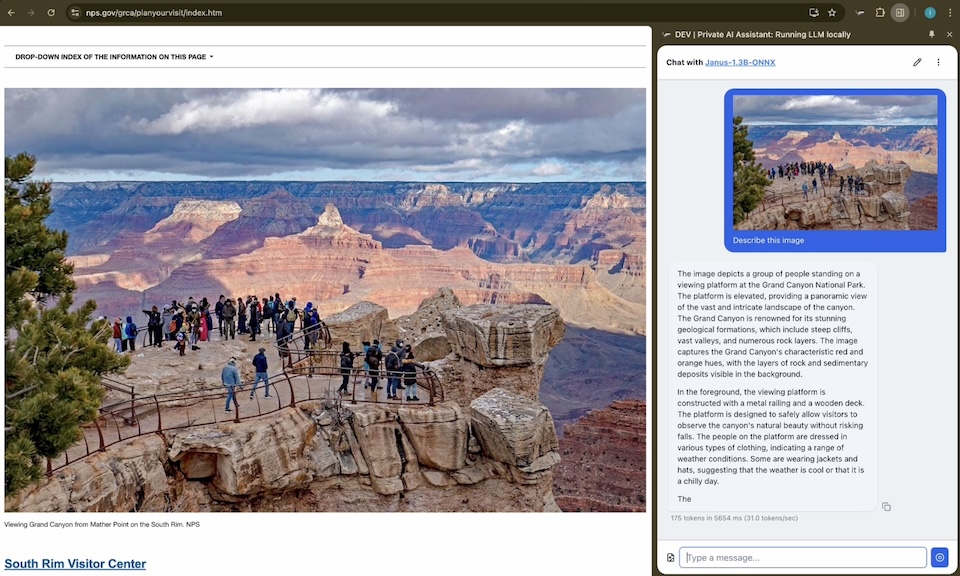
Vision + Text
Understand images and text together.
Our models support multimodal input. Upload an image and ask questions about it — all processed locally on your device.
1
Image Understanding
Describe photos, read handwriting, analyze charts and diagrams.
2
Multi-Image Support
Upload multiple images in a single conversation for comparison and analysis.
3
Drag & Drop Upload
Simply drag images into the chat or use the file picker.
0.8B params
compact yet capable
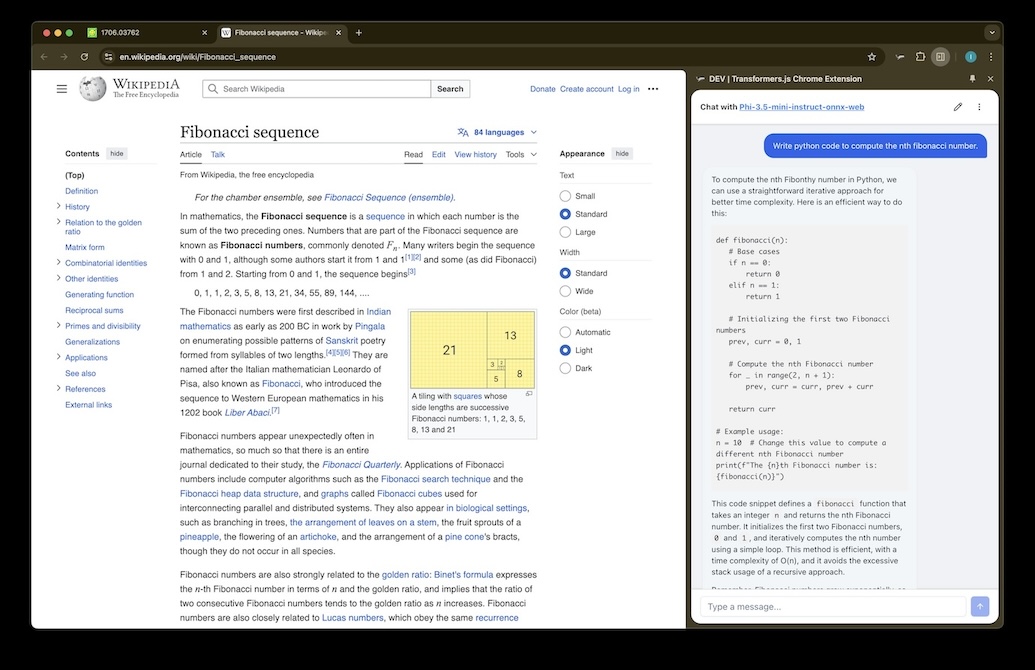
Full Control
Tune the model to your needs.
Adjust temperature, top-p, top-k, repetition penalty, and more. Like having a local AI playground with fine-grained control over generation behavior.
1
Generation Settings
Temperature, top-p, top-k, min-p, repetition penalty — all adjustable in real-time.
2
Real-Time Metrics
See tokens per second, time-to-first-token, and total generation time.
3
Stop & Reset
Interrupt generation at any time. Clear the conversation and start fresh.
~40 tok/s
on modern laptops
0.8B
Model Parameters
~40
Tokens per Second
0
Data Sent to Servers
100%
Local & Private
Ready to dive in?
No sign-up required. No data collected. Load the model and start chatting — it's that simple.